

Objectives
- Introduce Amazon SQS and Queues.
- Look into the different types of queues and their differences.
- Understand how Amazon SQS would be used in a decoupled application or service.
- Build a simple Django app integrating Amazon SQS.
Prerequisites
- Good knowledge of python.
- Knowledge of Django Rest Framework.
What is Amazon SQS?
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. Simply put, It is a service provided by AWS that uses the queue data structure underneath, to store messages it receives until they are ready to be retrieved.
What exactly is a queue?
A Queue is a data structure that takes in and returns data in the order of F.I.F.O (First in First Out). It's the same as a real-world queue, the first person to enter the queue is the first one to leave as well.
SQS Queues
SQS queues are queues we send messages to (JSON, XML, e.t.c.) and then later poll to retrieve those messages. The service sending the message is called a Producer and the service polling the message is called a Consumer. The size limit of a single message is 256KB.
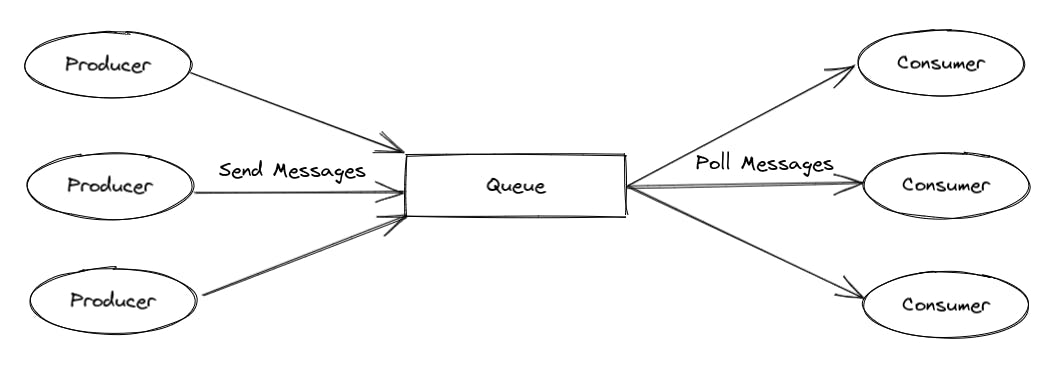 Image from dzone.com
Image from dzone.com
Amazon SQS provides us with two types of message queues:
- Standard Queue: These queues provide at-least-once delivery of messages, this means all messages are delivered at least once, however, some messages may be delivered more than once. It also provides best-effort ordering, which means its possible messages are not delivered in the order that they were received.
- FIFO Queue (First-in-First-out): These are queues designed for Only-Once delivery, meaning all messages will be processed exactly once. FIFO queue also guarantees ordered delivery, i.e, The FIRST message IN, is the FIRST message OUT(FIFO).
Looking at the above explanations, we might want to ask ourselves, Why exactly would we want to use a Standard Queue? Well,
- Standard Queues allow near an unlimited number of transactions per second while FIFO queues only allow processing of a max of 300 messages transactions per second without batching, and 3000 with batching.
- Standard queue is currently supported in all AWS regions, while FIFO, at the time of writing, is not.
Both are suited for different use cases. A FIFO queue is well suited for applications that highly depend on the order of the messages and have a low tolerance for duplicated messages. A standard Queue is suited for applications that are able to process duplicate and out-of-order messages.
Advantages of Amazon SQS
- Increased performance - SQS allows for asynchronous communication between different parts of an application.
- Increases Reliability - If the consumer service fails or crashes. Since the messages still exist in the queue, it can pick them up again when it's back online. This leads to increased reliability.
- Scalability - A 'standard SQS' queue allows close to an unlimited number of message transactions per second. This makes it easier for your service to scale from thousands of requests per second to millions.
- Buffer requests - SQS helps to prevent overloading a service with crazy amounts of requests. With SQS, the service can choose how many requests it wants to work on at any given time, and SQS will never return more than this to the service.
Example use-case for Amazon SQS
Imagine you have a service that currently:
- Takes in URL paths to large files from a user.
- Does some time-consuming processing on the file, and saves the result into the database.
- And eventually returns the result to the user.
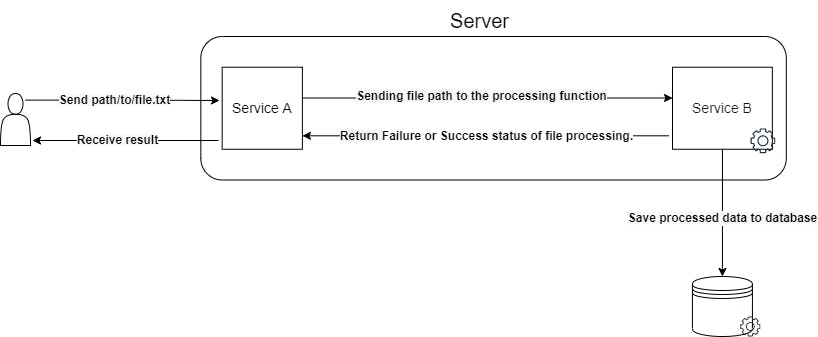
What are the possible problems here?
- If service B gets overloaded with a high amount of files to process, it could slow the server down, eventually leading to the server crashing.
- If the entire server ever happens to go down, it would lead to failure for all users currently using the service to process files.
How can amazon SQS be used to solve this? Using SQS, we can take out our file processing function and place it on a new dedicated server, hence "decoupling" service A from the file processing function(service B).
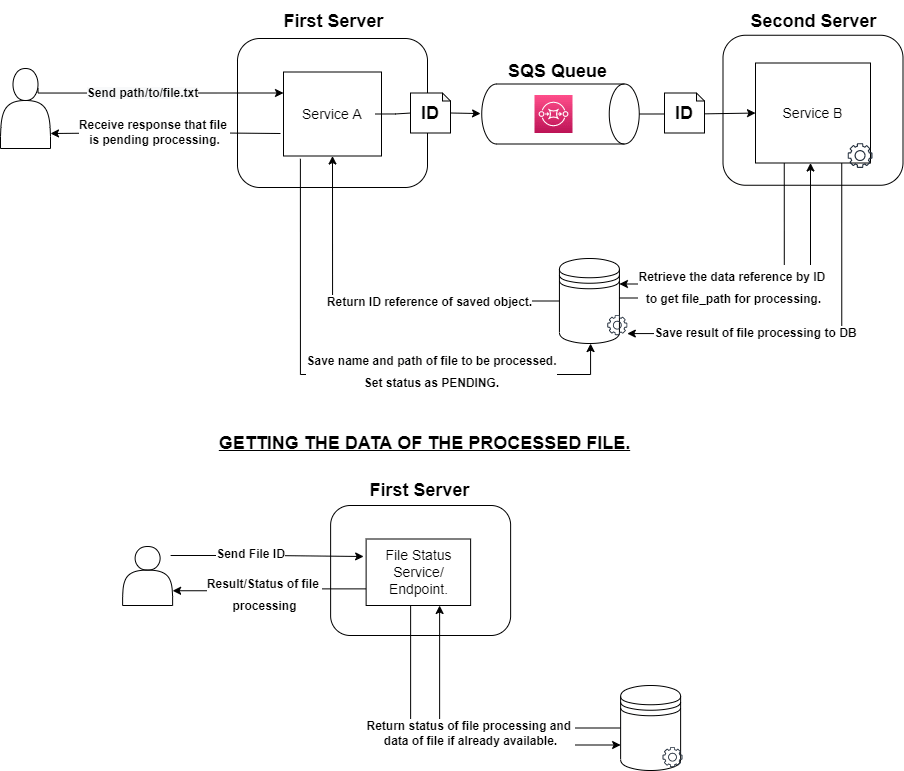
The flow of the service using SQS could now be as follows:
- The user sends a request to our server 1 with the file path for processing.
- Service A saves the name of the file and the file path to the database with a status field of "Pending" and gets the ID of the newly saved object.
- Service A sends a message to the queue containing the ID of the saved object before returning a response to the user indicating the file is now in the queue pending processing.
- Service B polls specific amounts of messages from the queue to process at its own pace(This prevents the server from getting overloaded and crashing). It then gets the ID's from those messages.
- Service B uses the ID to retrieve the saved object from the database, get the file path, and start processing the file.
- Once it succeeds or fails, it updates the stored object to an appropriate status (Succeeded/Failed).
Server 1 also has an endpoint that users can utilize to check up on the status of their file processing request and its data if it has already been processed successfully.
Project Setup
We will be building out the file processing service example. For this, we would need to create an aws account and get our aws access and secret access keys from the console. Once you've gotten your keys store them safely.
Let's also create our first Queue. With the search bar, navigate to the Amazon SQS.
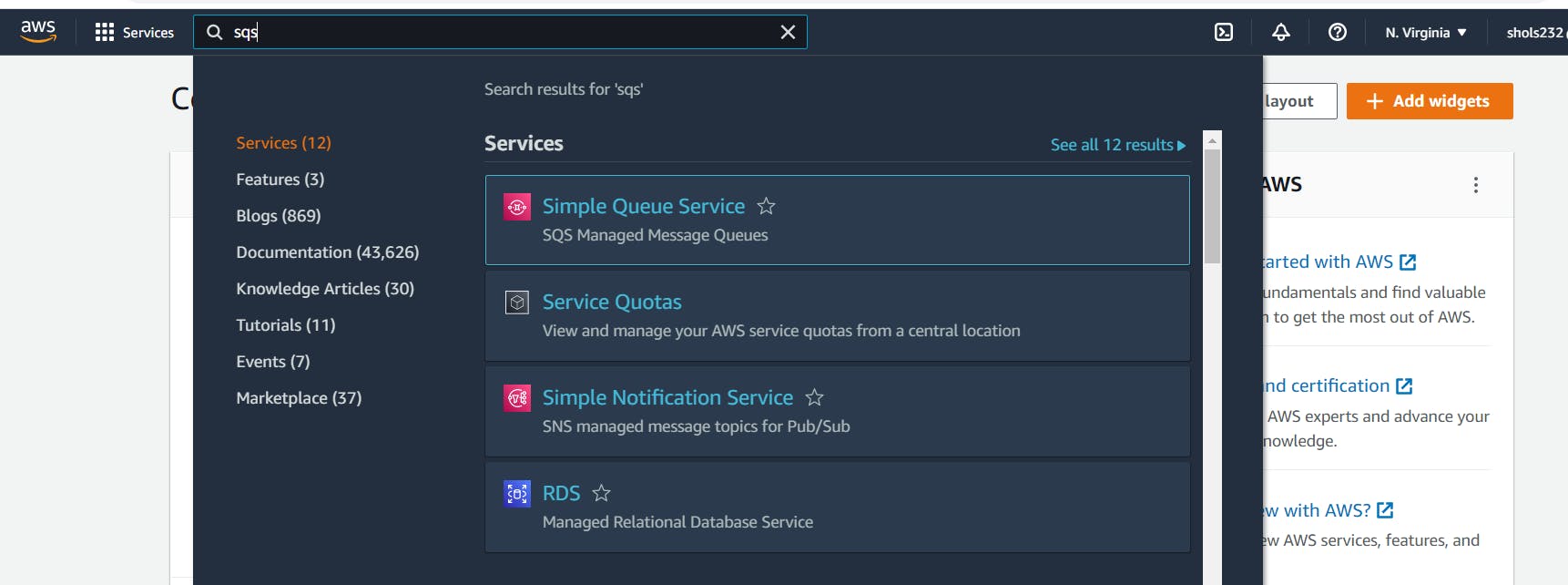
Now on the SQS page, click on Create queue. We are taken to the SQS Queue creation page and we see some options presented to us.
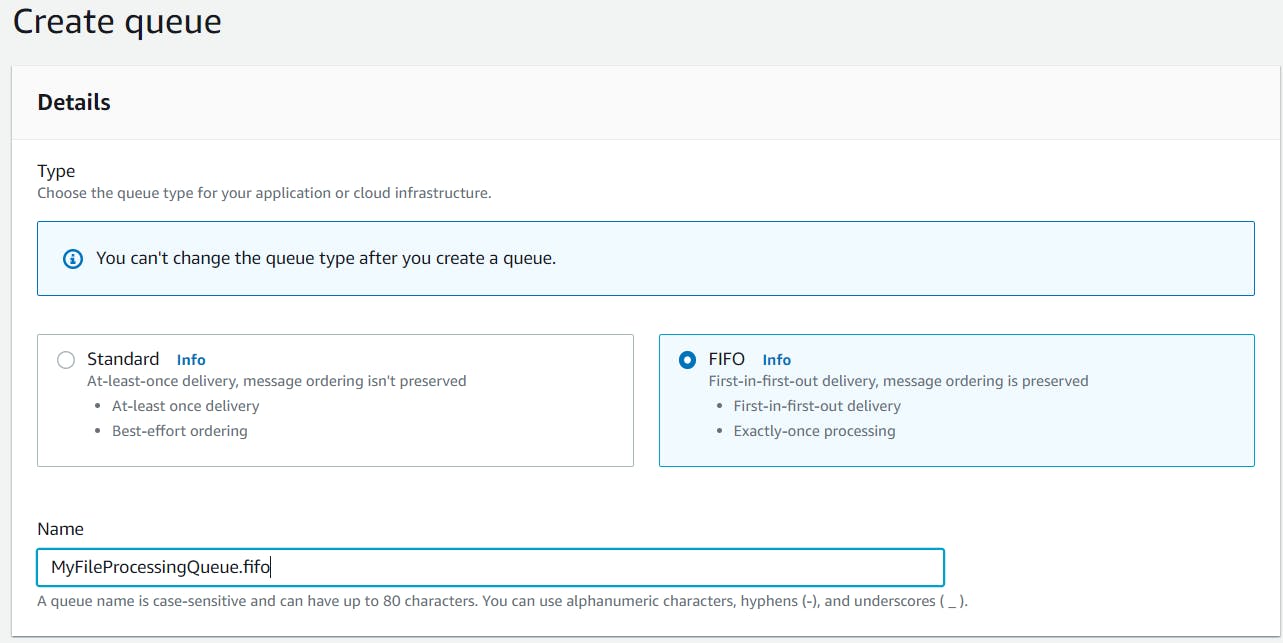
For this tutorial, Choose the FIFO Queue, and then enter a name for your queue. Note that FIFO queue names must end with .fifo. Look for the Content-based deduplication option and turn it on(This helps to prevent consumers from picking up a possible duplicate message from the queue). Leave every other option as the default and click Create queue at the bottom.
Copy the name of the Queue, in my case, MyFileProcessingQueue.fifo, and store it somewhere, we would be using it later. Also, take note of the region name where your queue is created, you can view it from the top right of the console. For me, that would be us-east-1.
Now into the Django part, let's begin by creating a new directory and setting up a new project.
$ mkdir amazon-sqs-django && cd amazon-sqs-django
$ python3.8 -m venv venv # --> Create virtual environment.
$ source venv/bin/activate # --> Activate virtual environment.
(venv)$ pip install django==4.0.5 djangorestframework==3.13.1
(venv)$ django-admin startproject core .
We will also install boto3 to help us communicate more easily with our SQS Queue.
(venv)$ pip install boto3==1.24.20
Next, let's create a Django app called file which will hold the models and logic for the entire service A.
(venv)$ python manage.py startapp file
Register the app in core/settings.py inside INSTALLED_APPS:
# *core/settings.py*
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'file', # new
]
Creating our File model
Inside file/models.py, add the following
# *file/models.py*
...
class File(models.Model):
class FileStatus(models.IntegerChoices):
PENDING = 0
PROCESSING = 1
PROCESSED = 2
FAILED = 3
lines_count = models.IntegerField(null=True)
file_size = models.IntegerField(null=True)
file_path = models.CharField(max_length=120)
status = models.IntegerField(choices=FileStatus.choices, default=FileStatus.PENDING)
...
This model will store some basic information that we "process" from the files. The status indicates what stage of the processing, the actual file is in. We have four status types:
- PENDING: This means the file has not yet been picked up for processing.
- PROCESSING: The file has been picked up, and work is being done on it currently.
- PROCESSED: The file was successfully processed; no issues were encountered.
- FAILED: Something went wrong somewhere; the file could not be processed correctly.
Creating the view
Inside the views.py, let's add the following
import boto3
from rest_framework.views import APIView
from .models import File
session = boto3.Session(
aws_access_key_id='<AWS_ACCESS_KEY_ID>', # replace with your key
aws_secret_access_key='<AWS_SECRET_ACCESS_KEY>', # replace with your key
)
sqs = session.resource('sqs', region_name='<AWS_REGION_NAME>') # replace with your region name
class FileView(APIView):
"""
Process file and saves its data.
:param file_path: path to file on a remote or local server
:return: status
"""
def post(self, request):
file_path = request.data.get('file_path')
file_obj = File.objects.create(file_path=file_path) # save file unprocessed.
# Get our recently created queue.
queue = sqs.get_queue_by_name(QueueName="MyFileProcessingQueue.fifo")
Using boto3, we instantiate a utility class sqs for interacting with the Amazon SQS resource. Then we create a view and now inside its post method, we get the file path from the user and save it into the database. The saved File object has a default status of PENDING which we previously set in the model class. We also get our queue by its name, which in my case, is MyFileProcessingQueue.fifo.
To send a message to our queue, let's update the view
import json # new
import boto3
from rest_framework.views import APIView
from rest_framework.response import Response # new
from .models import File
.....
class FileView(APIView):
def post(self, request):
.....
message_body = {
'file_id': str(file_obj.id)
}
# Send a message to the queue, so we can process this particular file eventually.
response = queue.send_message(
MessageBody=json.dumps(message_body),
MessageGroupId='messageGroupId'
)
# Let the user know the file has been sent to the queue and is PENDING processing.
return Response({"message": "File has been scheduled for processing..."},
status=200)
Here,
- We send an sqs message containing our saved File object ID, so we can later use it to retrieve the object from the database and get the file path to be processed. The
MessageGroupIdensures that all messages with the sameMessageGroupIdare processed in a FIFO order. Usually, this would be set to something unique like the user ID or session ID, but for simplicity, we use the string 'messageGroupId'. You can learn more about the possible parameters for the send_message method. - After sending the message to our SQS queue. We send a response immediately to the user letting them know their file is now in the queue pending processing, so they can go about their activities with our service without concern.
Your view should now look something like this:
# *file/views.py*
import json
import boto3
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import File
session = boto3.Session(
aws_access_key_id='<AWS_ACCESS_KEY_ID>', # replace with your key
aws_secret_access_key='<AWS_SECRET_ACCESS_KEY>', # replace with your key
)
sqs = session.resource('sqs', region_name='<AWS_REGION_NAME>') # replace with your region name
class FileView(APIView):
"""
Process file and saves its data.
:param file_path: path to file.
:return: status
"""
def post(self, request):
file_path = request.data.get('file_path')
file_obj = File.objects.create(file_path=file_path) # save file unprocessed.
# Get our recently created queue.
queue = sqs.get_queue_by_name(QueueName="MyFileProcessingQueue.fifo")
message_body = {
'file_id': str(file_obj.id)
}
# Send a message to the queue, so we can process this particular file eventually.
response = queue.send_message(
MessageBody=json.dumps(message_body),
MessageGroupId='messageGroupId'
)
# Let the user know the file has been sent to the queue and is PENDING processing.
return Response({"message": "File has been scheduled for processing..."},
status=200)
Testing what we have so far
First, let's connect the file app URLs to our project URLs. Inside the file folder, create a new file urls.py.
# file/urls.py
from django.urls import path
from .views import FileView
urlpatterns = [
path('process', FileView.as_view())
]
Now edit the core/urls.py file,
from django.contrib import admin
from django.urls import path, include # new
urlpatterns = [
path('admin/', admin.site.urls),
path('files/', include('file.urls')), # new
]
Next, make and run migrations
(venv)$ python manage.py makemigrations
(venv)$ python manage.py migrate
Now start the development server.
(venv)$ python manage.py runserver
For easy testing, we will create a file inside the root folder named test_file.txt and fill it up with 10 or more lines just so it's not empty. This will be our file to be processed. Now your folder path should look like
amazon-sqs-and-django
├── core
├── db.sqlite3
├── file
├── manage.py
├── test_file.txt
└── venv
Now, launch postman and test the http://127.0.0.1:8000/files/process endpoint with the absolute file path to the test_file.txt.
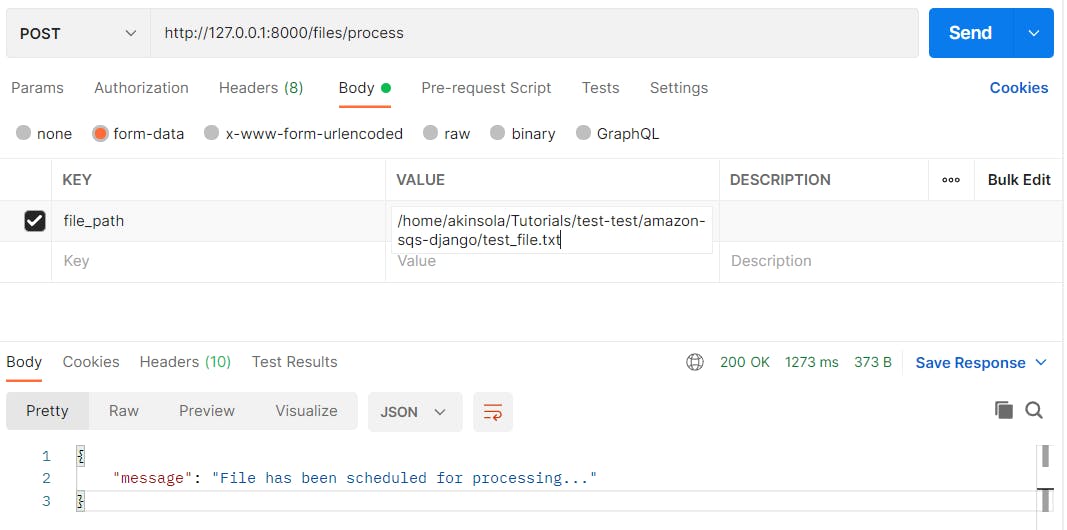
Now, let's head back over to the queues page on the AWS console and click our recently created queue - MyFileProcessingQueue.fifo. Then, on the top right of the new page, click Send and Receive messages.

Now, click on poll messages and click the first message that comes in, you should see the data we sent from the Django app.
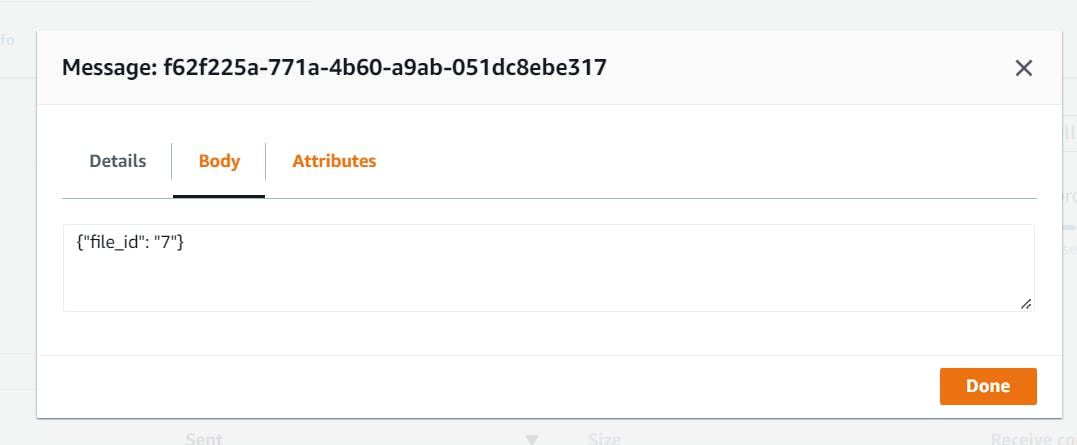
Now we know the first part of our service works. We are now able to send a message from our Django app into an SQS queue.
Conclusion and Next Steps
In this first part of this AWS SQS python and Django article, you learned the basics of queues in general and Amazon SQS, its advantages, and some of its use cases. We learned how to create a queue and built a Django app to send messages to that queue.
In the next article, we will
- Build out our
service B, the File processing service that will consume messages from the queue, process the file, and update the database. - We will also provide an endpoint for the user to check on the result of the file processing at any given point in time.
If you found this article useful or learned something new, consider leaving a thumbs up!
Till next time, happy coding!
Levi
EDIT: You can read part 2 of this article at Understanding amazon sqs with python and django part 2